什么是hadoop(单节点和多节点),spark-master和spark-worker?
问题描述 投票:1回答:2
我想了解以下术语:
hadoop(单节点和多节点)火花大师火花工人名字节点datanode
到目前为止,我了解的火花大师是工作执行者,负责处理所有火花工作者。 hadoop是hdfs(我们的数据所在的地方),spark工作者从那里读取添加到给他们的工作中的数据。如果我错了,请纠正我。
我还想了解namenode和datanode的作用。尽管我知道namenode的角色(具有所有datanode的元数据信息,并且应该只是一个(最好),但可以是两个),并且datanode可以是多个并具有数据。
datanode是否是相同的hadoop节点?
请在此说明我。
提前感谢。
2个回答
投票
SPARK体系结构:
火花使用master/worker architecture。有一个驱动程序与称为master的单个协调器进行对话,该协调器管理执行程序在其中运行的工人。

驱动程序和执行程序在各自的Java进程中运行。您可以在相同的(水平集群)或单独的机器(垂直集群)上或在混合的机器配置中运行它们。
节点不过是物理机器。
Hadoop NameNode和DataNode:
HDFS具有主/从体系结构。 HDFS群集由单个NameNode和管理文件系统名称空间并控制客户端对文件的访问的主服务器组成。此外,还有许多数据节点,通常是集群中每个节点一个,用于管理与它们所运行的节点相连的存储。 HDFS公开了文件系统名称空间,并允许用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组DataNode中。 NameNode执行文件系统名称空间操作,例如打开,关闭和重命名文件和目录。它还确定块到DataNode的映射。 DataNode负责处理来自文件系统客户端的读写请求。 DataNode还根据NameNode的指令执行块创建,删除和复制。
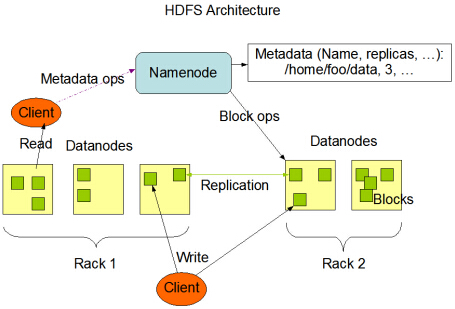
是的,DataNodes是Hadoop集群中的从节点。
请参阅文档以获取更多详细信息。
投票
Hadoop单节点具有1个Namenode(主节点)和1个Datanode(从节点)的Hadoop群集。 Namenode具有所有元数据,并将其分配给存储数据并完成处理的从属数据节点。
Hadoop多节点具有1个Namenode(主节点)和n个Datanode(从节点)的Hadoop集群
spark master与HDFS中的Namenode相同>
spark worker
与datanode相同,但spark worker仅用于处理未存储的数据。将事物放到上下文中(简单)-如果有1个Namenode和2个datanode(1GB内存)集群。 2 GB的文件将被拆分并存储在datanode上。与spark作业类似,将拆分以并行处理各个datanode(workers)上的此数据。
最新问题
- 有什么方法可以通过reactjs点击按钮将Antd表数据导出到Excel表中
- 训练 IP-Adapter plus 模型后出现推理错误
- 从字典中的键返回值的函数 - python
- 如何更改 Azure 应用服务以显示不同的时区?
- Next.js 应用程序的 Firebase 应用程序托管和云功能部署中的依赖关系问题
- 将二维数组的行按两列分组,并覆盖每组中无值的关联元素
- 如何正确访问地图值?
- Android 模拟器无法信任 Charles 代理证书
- 使用空手道1.5时不会生成Karate.log文件
- 简单矩阵乘法 - 替换长度错误[关闭]
- 为什么空手道场景和场景大纲在名称前生成括号?
- 按日期列对二维数组的行进行分组,并覆盖每组中无值的关联元素
- SFSpeechRecognizer 的冗余问题
- 信号值改变后调用函数
- flutter中sqflite的OnUpgrade并在没有该值时设置默认值
- 如何在拖动过程中使视图保持在用户手指的中心
- 旧的和奇异的 JVM 上 java.io.BufferedInputStream 的默认缓冲区大小是多少?
- C# 字符串前的“@”[重复]
- 在 MYSQL 中继续获取表和视图
- 尝试从 C 调用 ruby 方法时如何在 C 代码中“要求”第三方模块?