为什么即使代码运行没有错误,Spacy 也不执行训练管道?
问题描述 投票:0回答:1
我正在使用 Spacy 版本 3.5.0 使用一些虚拟数据训练自定义 NER 模型。下面给出了我的整个代码和虚拟数据。 这与此链接的第二部分中给出的代码完全相同。代码运行良好,但它只执行到训练的初始化管道步骤,并且训练管道未执行。
知道为什么训练管道没有被执行吗?
import pandas as pd
import os
from tqdm import tqdm
from spacy.tokens import DocBin
train = [
("An average-sized strawberry has about 200 seeds on its outer surface and are quite edible.",{"entities":[(17,27,"Fruit")]}),
("The outer skin of Guava is bitter tasting and thick, dark green for raw fruits and as the fruit ripens, the bitterness subsides. ",{"entities":[(18,23,"Fruit")]}),
("Grapes are one of the most widely grown types of fruits in the world, chiefly for the making of different wines. ",{"entities":[(0,6,"Fruit")]}),
("Watermelon is composed of 92 percent water and significant amounts of Vitamins and antioxidants. ",{"entities":[(0,10,"Fruit")]}),
("Papaya fruits are usually cylindrical in shape and the size can go beyond 20 inches. ",{"entities":[(0,6,"Fruit")]}),
("Mango, the King of the fruits is a drupe fruit that grows in tropical regions. ",{"entities":[(0,5,"Fruit")]}),
("undefined",{"entities":[(0,6,"Fruit")]}),
("Oranges are great source of vitamin C",{"entities":[(0,7,"Fruit")]}),
("A apple a day keeps doctor away. ",{"entities":[(2,7,"Fruit")]})
]
db = DocBin() # create a DocBin object
for text, annot in tqdm(train): # data in previous format
doc = nlp.make_doc(text) # create doc object from text
ents = []
for start, end, label in annot["entities"]: # add character indexes
span = doc.char_span(start, end, label=label, alignment_mode="contract")
if span is None:
print("Skipping entity")
else:
ents.append(span)
doc.ents = ents # label the text with the ents
db.add(doc)
db.to_disk("./train.spacy") # save the docbin object
!python -m spacy init fill-config base_config.cfg config.cfg
!python -m spacy train config.cfg --output ./output --paths.train ./train.spacy --paths.dev ./train.spacy
预期产量
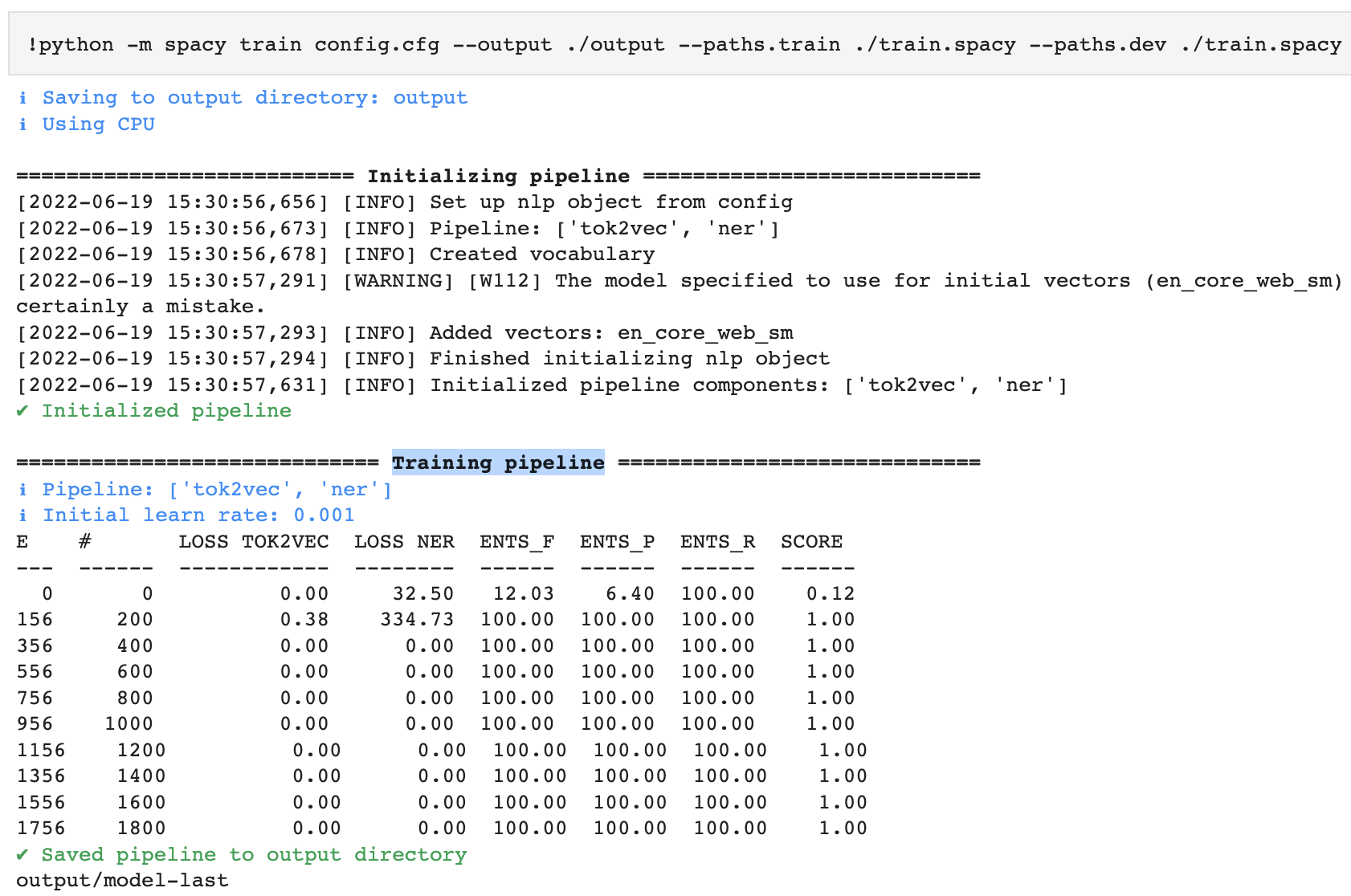
我得到的输出
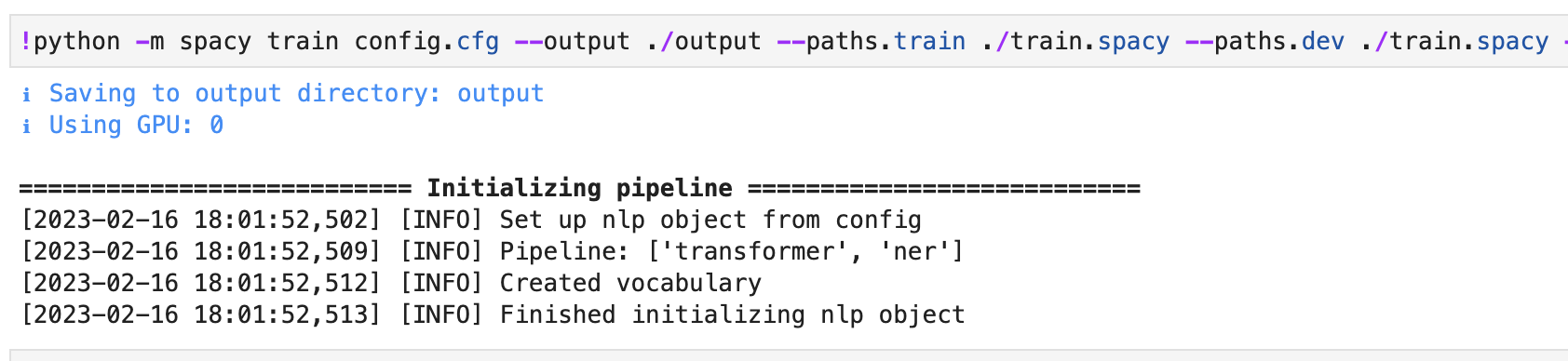
1个回答
0
投票
投票
我自己在寻找宽敞的火车资源时发现了这个,并注意到最后一行有问题。
!python -m spacy train config.cfg --output ./output --paths.train ./train.spacy --paths.dev ./train.spacy
本例中的训练数据集和开发数据集均来自同一来源“./train.spacy”。可能正是这种重叠导致训练在第一个时期之后结束,其中评估分数从 0.12 跃升至 1.00。
最新问题
- Node.js 返回不同的 REACT 页面视图
- Spring WebClient 抛出 javax.net.ssl.SSLException: SSLEngine 在大量使用时已关闭
- 如何在laravel中只获取一行?
- 如何通过空格和问号、感叹号和句点等特殊字符将 Swift 字符串拆分为数组?
- Flutter 中的 iOS 下拉小部件的名称是什么?
- 为什么我在 flutter 项目中添加启动器图标时出现错误?
- InterBase 在数据库中找到这些字符(代码 13:回车(CR) 代码 10:换行(LF))
- 如何使用 Amazon S3 将默认图像添加到 django ImageField 以进行文件存储?
- 如何刷新访问令牌。不打开图形 API 浏览器?在 facebook GraphAPI 中
- Promise 重新定义不会影响原生函数返回的 Promise
- 在 Google Sheets 公式中指定 24 小时内的时间跨度/持续时间常数
- 调整 MenuBarExtra 窗口的大小
- Kubernetes ingress-nginx 给出 502 错误(网关错误)
- Oracle APEX 动态操作调用包抛出错误“ORA-06550:第 11 行,第 19 列:PLS-00302:必须声明组件 'GET_EMP_INFO'”
- 将 TextField 和 FlatButton 对齐在一行中
- 从 BigQuery 到时态表的查询视图,以便存储 API 可以使用
- 滑动工作不正常。我想要从左边开始。从右边来
- 我的 Nestjs 项目中使用 mocha 和 chai 时出现错误:TypeError [ERR_UNKNOWN_FILE_EXTENSION]:未知文件扩展名“.ts”
- 在 Windows 上,neovim 在使用 harpoon 时崩溃
- 使用相同的函数和命名约定在几个不同的子集上进行 mutate()
© www.soinside.com 2019 - 2024. All rights reserved.