创建人工智能聊天机器人,但出现回溯错误
问题描述 投票:0回答:3
我正在尝试用 python 创建一个人工智能聊天框。我尝试按照本教程进行操作:https://techwithtim.net/tutorials/ai-chatbot/part-1/但是我收到了很多弃用错误并收到一些回溯错误。 这是代码:
import json
import random
import tensorflow
import tflearn
import numpy
import sys
import pickle
import nltk
from nltk.stem.lancaster import LancasterStemmer
stemmer = LancasterStemmer()
nltk.download('punkt')
with open("trainingData.json") as file:
data = json.load(file)
try:
with open("data.pickle", "rb") as f:
words, labels, training, output = pickle.load(f)
except:
words = []
labels = []
docs_x = []
docs_y = []
for intent in data["intents"]:
for pattern in intent["patterns"]:
wrds = nltk.word_tokenize(pattern)
words.extend(wrds)
docs_x.append(wrds)
docs_y.append(intent["tag"])
if intent["tag"] not in labels:
labels.append(intent["tag"])
words = [stemmer.stem(w.lower()) for w in words if w != "?"]
words = sorted(list(set(words)))
labels = sorted(labels)
training = []
output = []
out_empty = [0 for _ in range(len(labels))]
for x, doc in enumerate(docs_x):
bag = []
wrds = [stemmer.stem(w.lower()) for w in doc]
for w in words:
if w in wrds:
bag.append(1)
else:
bag.append(0)
output_row = out_empty[:]
output_row[labels.index(docs_y[x])] = 1
training.append(bag)
output.append(output_row)
training = numpy.array(training)
output = numpy.array(output)
with open("data.pickle", "wb") as f:
pickle.dump((words, labels, training, output), f)
tensorflow.reset_default_graph()
net = tflearn.input_data(shape=[None, len(training[0])])
net = tflearn.fully_connected(net, 8)
net = tflearn.fully_connected(net, 8)
net = tflearn.fully_connected(net, len(output[0]), activation="softmax")
net = tflearn.regression(net)
model = tflearn.DNN(net)
try:
model.load("model.tflearn")
except:
model.fit(training, output, n_epoch=1000, batch_size=8, show_metric=True)
model.save("model.tflearn")
def bag_of_words(s, words):
bag = [0 for _ in range(len(words))]
s_words = nltk.word_tokenize(s)
s_words = [stemmer.stem(word.lower()) for word in s_words]
for se in s_words:
for i, w in enumerate(words):
if w == se:
bag[i] = 1
return numpy.array(bag)
def chat():
print("Start talking with the bot (type quit to stop)!")
while True:
inp = input("You: ")
if inp.lower() == "quit":
break
results = model.predict([bag_of_words(inp, words)])
results_index = numpy.argmax(results)
tag = labels[results_index]
for tg in data["intents"]:
if tg['tag'] == tag:
responses = tg['responses']
print(random.choice(responses))
chat()
这是我遇到的错误。如何修复弃用错误、回溯错误?
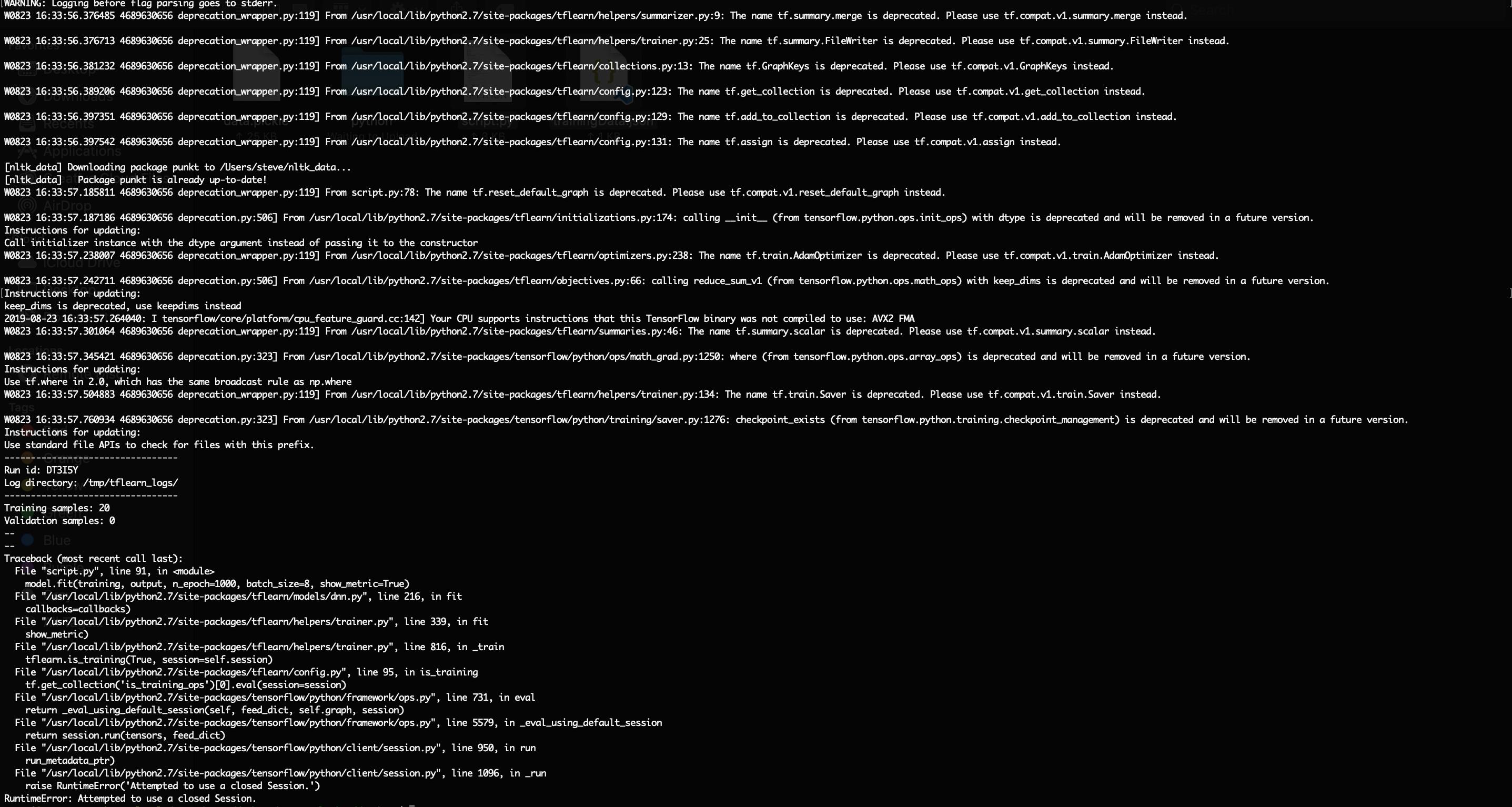
这是错误的文本:
Run id: VOB3W4
Log directory: /tmp/tflearn_logs/
---------------------------------
Training samples: 20
Validation samples: 0
--
--
Traceback (most recent call last):
File "script.py", line 91, in <module>
model.fit(training, output, n_epoch=1000, batch_size=8, show_metric=True)
File "/usr/local/lib/python2.7/site-packages/tflearn/models/dnn.py", line 216, in fit
callbacks=callbacks)
File "/usr/local/lib/python2.7/site-packages/tflearn/helpers/trainer.py", line 339, in fit
show_metric)
File "/usr/local/lib/python2.7/site-packages/tflearn/helpers/trainer.py", line 816, in _train
tflearn.is_training(True, session=self.session)
File "/usr/local/lib/python2.7/site-packages/tflearn/config.py", line 95, in is_training
tf.get_collection('is_training_ops')[0].eval(session=session)
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/framework/ops.py", line 731, in eval
return _eval_using_default_session(self, feed_dict, self.graph, session)
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/framework/ops.py", line 5579, in _eval_using_default_session
return session.run(tensors, feed_dict)
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 950, in run
run_metadata_ptr)
File "/usr/local/lib/python2.7/site-packages/tensorflow/python/client/session.py", line 1096, in _run
raise RuntimeError('Attempted to use a closed Session.')
RuntimeError: Attempted to use a closed Session.
3个回答
3
投票
投票
启动文件
"model.tflearn"try/exceptfit()时,
save() 应该捕获错误
try:
model.load("model.tflearn")
except:
model.fit(training, output, n_epoch=1000, batch_size=8, show_metric=True)
model.save("model.tflearn")
但似乎这个错误关闭了
tf.session()fit()如果用
try/exceptload()fit()save()model.fit(training, output, n_epoch=1000, batch_size=8, show_metric=True)
model.save("model.tflearn")
创建文件
"model.ftlearn"try/exceptload()更好的解决方案应该检查文件是否存在 - 但它将数据保存在几个文件中
"model.tflearn.index""model.tflearn.meta""model.tflearn.data-00000-of-00001""model.tflearn"使用
import os
if os.path.exists("model.tflearn.meta"):
model.load("model.tflearn")
else:
model.fit(training, output, n_epoch=1000, batch_size=8, show_metric=True)
model.save("model.tflearn")
而不是
try:
model.load("model.tflearn")
except:
model.fit(training, output, n_epoch=1000, batch_size=8, show_metric=True)
model.save("model.tflearn")
编辑:看来这个问题至少存在2年了:RuntimeError:尝试在tflearn中使用关闭的会话
0
投票
投票
您好,看起来您使用的是tensorflow,请尝试使用OpenAI 和next.js。我在这篇博文中解释了这一点:https://www.brendanmulhern.blog/posts/make-your-own-ai-chatbot-website-with-next-js-and-openai-course。
-1
投票
投票
尝试这样做:
try:
model.load("model3.tflearn")
except:
model = tflearn.DNN(net)
model.fit(training,output, n_epoch = 1000, batch_size = 8, show_metric = True)
model.save("model3.tflearn")
最新问题
- Azure OpenAI Studio Playground:在向任何函数提交输出时,我的助手总是返回未定义的错误
- 如何对Bull.js与Redis服务器的连接实现完整而非部分的TLS保护?
- Nuget 资源从 https 更改为 http
- 不同值时如何在同一行返回结果
- 我可以将 boost::intrusive::rbtree 与 stateful_value_traits 一起使用吗?
- 确定next.js中的客户端/服务器组件
- 按照Ieee-754单精度格式实现浮点加法器但移位错误
- 如何在Python中通过OR-Tools使用sorted()和min()函数?
- 来自 openai python SDK 的 AsyncAzureOpenAI 客户端支持自定义快速 API 端点
- 如果我想使用过去/未来数百万年的日期和时间,我该怎么做?
- 使用 docker-compose 进行 LangGraph 部署
- 如何使用 WebDriver Sampler (JMeter) 中的 JMeter 属性 props.get props.put
- 从 winit 获取 windows-rs HWND?
- 迭代所有用户 - firestore
- Python 2 中对象和实例之间的区别?
- 如何使用 PyMuPDF 将 unicode 文本插入 PDF?
- 使用多个 PDF 矢量数据库从一个 PDF 中检索信息
- 在连接中使用字符串值和 CONCAT 作为表名
- 在 ubuntu 23.04 或任何非 LTS 版本中安装 Cloudflare warp cli 存在问题 [已关闭]
- 使用列作为带有 concat 的表连接
© www.soinside.com 2019 - 2024. All rights reserved.