DDIA Thrift CompactProtocol 编码
问题描述 投票:0回答:2
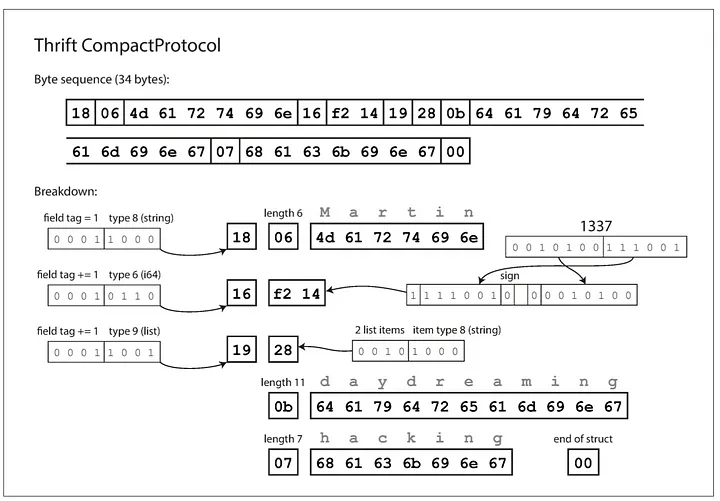
当我阅读 DDIA 第 119 页时,我在 Trift CompactProtocol 中看到,当对可变长度的 int64 进行编码时。
示例取自 DDIA
要编码的以 10 为基数的数字:1337 它被编码为 1|111001|0 0|0010100
1st byte: 1|111011|0 --->
the first 1 represents there are more data coming in after this byte
then 111011 is the actual coding of 37 (i assuem they use little endian)
the last 0 represent the sign +
2nd byte: 0|0010100
我的问题是,37和13如何编码为111011和0010100?他们不应该是100101和1101吗?谢谢你
我在网上搜索过,但似乎这很简单,没有人对此表示怀疑:(
2个回答
投票
十进制
133705390000010100111001设计数据密集型应用程序对BinaryProtocol与Thrift CompactProtocol有清晰、全面的解释和比较 Martin Kleppmann(第 4 章编码和进化)发现通过谷歌搜索的前三个链接DDIA“Thrift CompactProtocol”:
- https://sunnyleeyun.medium.com/ddia-summary-chapter-4-encoding-and-evolution-02e81c897677
- https://www.oreilly.com/library/view/designing-data-intense-applications/9781491903063/ch04.html
- https://miranpark.com/leetcode/posts/ddia-ch-4/
Thrift CompactProtocol 编码在语义上等同于 BinaryProtocol,但正如您在图 4-3 中看到的,它打包了 相同的信息仅存入 34 个字节。它通过打包字段来做到这一点 将类型和标签号转换为单个字节,并使用可变长度 整数。它没有使用完整的八个字节来表示数字 1337,而是 以两个字节编码,每个字节的最高位用于 指示是否还有更多字节。这意味着
和–64之间的数字被编码在一个字节中,数字63和–8192之间用两个字节编码,等等。更大 数字使用更多字节。8191

投票
整数使用所谓的“ZigZag 编码”进行编码。一旦你认真思考它,它实际上非常简单。
def intToZigZag(n: Int): Int = (n << 1) ^ (n >> 31)
def zigzagToInt(n: Int): Int = (n >>> 1) ^ - (n & 1)
def longToZigZag(n: Long): Long = (n << 1) ^ (n >> 63)
def zigzagToLong(n: Long): Long = (n >>> 1) ^ - (n & 1)
背后的理论是,接近零的数字比接近数据类型限制的值出现在普通数据中的概率更高。因此,符号位从前面删除并放置在末尾,从而为较小的数字提供比较大的数字更不重要的位。
可以删除前导零,因为这主要是冗余信息。唯一需要注意的是,您需要一个控制位来告诉可变长度字节序列在哪里结束,这就是为什么“有效负载”位被分为七位组,为“控制位”留出空间。
因此,当编码 dec 1337 = bin 0000 0101 0011 1001 时,数据被分割(记住 LE)为 7 位 0111001 和剩余 5 位 01010,这导致
ctrl | data | sign
1|111001|0
0|001010|0
或十六进制 F214。不知道为什么那张图片中的井号来自哪里,但这应该是 F。
{kind=link}
我在网上搜索过,但似乎这很简单,没有人对此表示怀疑:(
由于这是 FOSS,有时在完全意想不到和不合逻辑的地方也有可用的文档;-) 例如: https://github.com/apache/thrift/blob/master/doc/specs/thrift-compact-protocol .md 或 https://protobuf.dev/programming-guides/encoding/
最新问题
- 当refit=True时,为什么要在RandomizedSearchCV之后进行额外的拟合?
- 通过子字符串列表过滤DataFrame
- 在docker中使用buildkit并运行--mount,为什么cabal install下载缓存的包?
- 在分离器中读取多个帧
- 为什么 tls.Client 失败并显示消息:第一条记录看起来不像 TLS 握手
- 大师冥想错误:ESP32 上的 Core 1 Panic'ed(禁止加载)
- 从 PDF 中提取包含空单元格且没有可见边缘的表格
- 打开表单时输入参数值对话框
- 闪亮:<-: replacement has length zero when using wrapping X Axis Label
- Excel 夜班时间
- 为什么我在向此端点发送 HTTP 请求时收到此错误?使用 Spring Boot
- 如何调用传入 lambda 表达式的函数?
- Wix.com - 是否可以从集合中引用联系人(或成员)?
- 为 infix 定义一个方案函数
- XML LINQ 匹配麻烦
- 星图质心
- 如何在C++中将原始指针转换为唯一指针
- 过滤器锁定算法
- Remark 和 rehype 无法在应用程序路由器的 nextjs 中正确转换 mdx
- 我的不和谐机器人一直受到速率限制