使用 pandas 中的数据透视表计算特定数据的所有缺失值
问题描述 投票:0回答:1
我正在研究这个名为
titanic.csv](https://i.sstatic.net/LKGk47dr.png)](https://i.sstatic.net/fX7IWn6t.png)
我需要计算
childwho我尝试过这个解决方案:
pd.pivot_table(df[df['who'] == 'child'],
index='sex',
aggfunc=lambda x: x.isnull().sum(),
margins=True) # to sum all missing values based on gender
但我得到这个输出: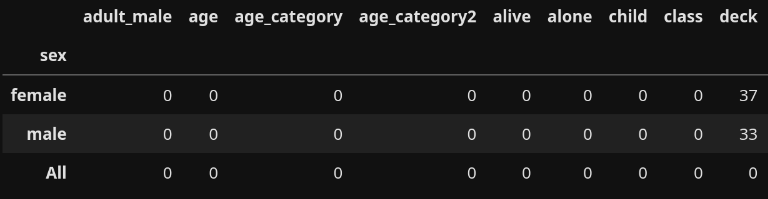
我的代码问题出在哪里?我应该使用其他方法来创建数据透视表吗?
1个回答
0
投票
投票
如果您只想要孩子的每个特征的缺失值数量,您可以使用 isna():
data = {'survived': [0, 1, 1, 1, 0],
'pclass': [3, 1, None, 1, 3],
'sex': ['male', 'female', 'female', 'female', 'male'],
'age': [22, 38, None, None, 35],
'class': ['Third', 'First', None, 'First', 'Third'],
'who': ['man', 'woman', 'child', 'child', 'man'],
'deck': [None, 'C', None, 'C', None],
'alive': ['no', 'yes', 'yes', 'yes', 'no'],
'alone': [False, False, True, False, True] }
df = pd.DataFrame(data)
display(df[df["who"] == "child"].isna().sum())
survived 0
pclass 1
sex 0
age 2
class 1
who 0
deck 1
alive 0
alone 0
最新问题
- 在Keycloak上导出大用户
- 展会通知安排
- 在哪里可以找到有关 CSON(咖啡脚本对象表示法)的指南?
- 改变多个变量以创建多个新变量
- 为什么我不能为 std::vector 元素取别名?
- 如何仅使用 CSS 将绝对元素自动居中在相对父元素中?
- 我正在尝试编写一个子过程,如果 IT 列值等于 OO,它将删除所有表行
- StandardScaler 的管道方法是否可以推广到基于树的集成或神经网络?
- React Native - 博览会通知安排
- 正则表达式仅排除小写字符串,但保存包含大写字母的字符串
- Milvus 数据插入过程中多线程 Rendezvous 错误 - 如何修复?
- 替换 Gmail 和 Chromium 中的默认鼠标光标
- 将 target: 'es5' 添加到 webpack.config.js 文件时出现奇怪的错误
- 无法使用 Cpanel 从本地服务器发送电子邮件
- 在glibc源码中哪里可以找到select()源代码?
- git 部分克隆垃圾收集
- C 库函数的源代码在哪里?
- Pytest 夹具未使用给定参数运行 x 次
- 我的 HTML5 和 CSS 项目出现 Vercel 部署错误 404
- 从 SCCS 迁移到 Git
© www.soinside.com 2019 - 2024. All rights reserved.