InceptionResnetV2 STEM 块 keras 实现与原始论文中的不匹配?
问题描述 投票:0回答:1
我一直在尝试将 Keras 实现中的 InceptionResnetV2 模型摘要与他们论文中指定的模型摘要进行比较,并且在涉及 filter_concat 块时似乎没有表现出太多相似之处。
模型的第一行
summary()Model: "inception_resnet_v2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 512, 512, 3) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 255, 255, 32) 864 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 255, 255, 32) 96 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 255, 255, 32) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 253, 253, 32) 9216 activation_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 253, 253, 32) 96 conv2d_2[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 253, 253, 32) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 253, 253, 64) 18432 activation_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 253, 253, 64) 192 conv2d_3[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 253, 253, 64) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 126, 126, 64) 0 activation_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 126, 126, 80) 5120 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 126, 126, 80) 240 conv2d_4[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 126, 126, 80) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 124, 124, 192 138240 activation_4[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 124, 124, 192 576 conv2d_5[0][0]
__________________________________________________________________________________________________
activation_5 (Activation) (None, 124, 124, 192 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 61, 61, 192) 0 activation_5[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 61, 61, 64) 12288 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_9 (BatchNor (None, 61, 61, 64) 192 conv2d_9[0][0]
__________________________________________________________________________________________________
activation_9 (Activation) (None, 61, 61, 64) 0 batch_normalization_9[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 61, 61, 48) 9216 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 61, 61, 96) 55296 activation_9[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 61, 61, 48) 144 conv2d_7[0][0]
__________________________________________________________________________________________________
batch_normalization_10 (BatchNo (None, 61, 61, 96) 288 conv2d_10[0][0]
__________________________________________________________________________________________________
activation_7 (Activation) (None, 61, 61, 48) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
activation_10 (Activation) (None, 61, 61, 96) 0 batch_normalization_10[0][0]
__________________________________________________________________________________________________
average_pooling2d_1 (AveragePoo (None, 61, 61, 192) 0 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
.
.
.
many more lines
在他们的论文的图3(下附图)中,显示了InceptionV4和InceptionResnetV2的STEM块是如何形成的。在图 3 中,STEM 块中有三个过滤器串联,但在我上面向您展示的输出中,串联似乎是顺序 maxpooling 或类似内容的混合(第一个串联应该出现在 max_pooling2d_1 之后附近)
)。它按照串联应做的那样增加了过滤器的数量,但没有进行串联。过滤器似乎是按顺序放置的!有人知道这个输出中发生了什么吗?和论文中描述的作用一样吗?为了比较,我找到了一个
InceptionV4 keras 实现,他们似乎确实在 concatenate_1
中为 STEM 块中的第一个串联执行了 filter_concat。这是
summary()第一行的输出。
Model: "inception_v4"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 512, 512, 3) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 255, 255, 32) 864 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 255, 255, 32) 96 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 255, 255, 32) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 253, 253, 32) 9216 activation_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 253, 253, 32) 96 conv2d_2[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 253, 253, 32) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 253, 253, 64) 18432 activation_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 253, 253, 64) 192 conv2d_3[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 253, 253, 64) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 126, 126, 96) 55296 activation_3[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 126, 126, 96) 288 conv2d_4[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 126, 126, 64) 0 activation_3[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 126, 126, 96) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 126, 126, 160 0 max_pooling2d_1[0][0]
activation_4[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 126, 126, 64) 10240 concatenate_1[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 126, 126, 64) 192 conv2d_7[0][0]
__________________________________________________________________________________________________
activation_7 (Activation) (None, 126, 126, 64) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 126, 126, 64) 28672 activation_7[0][0]
__________________________________________________________________________________________________
.
.
.
and many more lines
因此,如论文中所示,两种架构的第一层应该相同。或者我错过了什么?
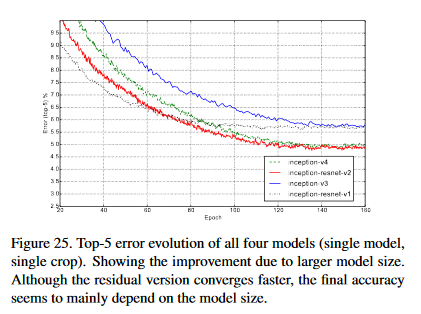
编辑:我发现,Keras 的 InceptionResnetV2 的实现不遵循InceptionResnetV2 的 STEM 块,而是InceptionResnetV1的实现(来自他们论文的图 14,附在下面)。在 STEM 块之后,它似乎很好地遵循了 InceptionResnetV2 的其他块。
InceptionResnetV1 的性能不如 InceptionResnetV2(图 25),因此我对使用 V1 中的块而不是 keras 的完整 V2 持怀疑态度。我会尝试从我找到的 InceptionV4 中删除 STEM,并放入 InceptionResnetV2 的延续。同样的问题已在 tf-models github 中关闭,没有任何解释。如果有人感兴趣,我将其留在这里:
https://github.com/tensorflow/models/issues/1235
编辑2:出于某种原因,GoogleAI(Inception架构的创建者)在发布代码时在他们的博客中展示了“inception-resnet-v2”的图像。但 STEM 模块是来自 InceptionV3 的模块,而不是论文中指定的 InceptionV4 模块。因此,要么论文是错误的,要么代码由于某种原因没有遵循论文。
![Figure 3 of the original paper. The schema for stem of the pure Inception-v4 and Inception-ResNet-v2 networks. [...]](https://i.sstatic.net/uxXNz.png)

1个回答
投票
它取得了类似的结果。
我刚刚收到一封电子邮件,确认了来自 Google 高级研究科学家 Alex Alemi 的错误,他也是关于发布 InceptionResnetV2 代码的博客文章的原始发布者。看起来在内部实验期间,STEM 块被切换了,释放就保持这样。[...] 不完全确定发生了什么,但代码 显然是真理的来源,因为被释放的 检查点是针对同时发布的代码的。 当我们在的时候 开发架构时我们做了很多内部工作 实验中,我想在某个时刻,茎被改变了。不是 当然我现在有时间更深入地挖掘,但就像我说的, 已发布的检查点是已发布代码的检查点 通过运行评估管道来验证自己。 我同意你的看法 看起来这似乎是使用原始的 Inception V1 主干。 最好的问候,
亚历克斯·阿莱米
我将更新这篇文章并对此主题进行更改。
更新
:Christian Szegedy,也是原始论文的出版商,只是同意之前的邮件: 最初的实验和模型是在 DistBelief 中创建的,这是一个早于 Tensorflow 的完全不同的框架。
一年后添加了 TF 版本,可能与原始模型存在差异,但确保达到类似的结果。
因此,由于它取得了相似的结果,因此您的实验将大致相同。
最新问题
- 由于 pytest-json-report 插件导致的 Pytestpluggy._manager.PluginValidationError
- 如何在Flutter中渲染特定行数的Wrap?
- HMR 尚未针对模块块格式实现
- 断开通话后麦克风无法工作的问题
- 通过切割2条边来分割图
- Android studio 覆盖率测试缺失(灰色)
- OpenXML 用实际图像替换图像占位符会替换所有占位符
- 如何解决图像/视频文件的Playstore警告
- 如何删除Linux文本中的所有特殊字符
- 如何将 pandas.series 结果转换为整数?
- SurveyJS 错误?问题名称=“0”导致选项不显示在逻辑中
- ConcurrentDictionary.GetOrAdd - 仅在不为空时添加
- 如何在选中文本时实现复制、查找、翻译、搜索网络和共享?
- 为什么 Windows 上的 cmake 指定重复的 SWIG python 语言指示?
- 如何将此 pandas.series 结果转换为整数?
- 检查类型名是否可以与元素类型一起复制构造
- 为什么对 cv wait 和 pop() 使用单独的锁会导致分段错误?
- Alembic 在自动生成期间不断删除和重新创建外键
- API 和 Web 工具之间的 Pagespeed 结果不同
- MAUI - 更改 iOS 的 AppIcon 和 SplashScreen