df.map() 在另一个 df.apply() 中的行为
问题描述 投票:0回答:1
我发现这个代码非常有趣。我稍微修改了代码以改善问题。本质上,该代码使用一个 DataFrame 使用
pd.stylet1 = pd.DataFrame({'x':[300,200,700], 'y':[100,300,200]})
t2 = pd.DataFrame({'x':['A','B','C'], 'y':['C','B','D']})
def highlight_cell(val, props=''):
return props if val > 200 else ''
t2.style.apply(lambda x: t1.map(highlight_cell, props='background-color:yellow'), axis=None)
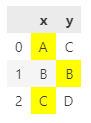
但是有人能解释一下最后一行是如何工作的吗?我找不到 Pandas 文档来阐明
df.map()df.apply()对我来说,代码读起来就像 对于 t1 中的每个项目,立即将
highlight_cell()for x in all_items_in_t1:
yield [highlight_cell(y) for y in all_items_in_t2]
但是,输出表示 对于 t1 中的每个项目,仅将
highlight_cell()for x, y in zip(all_items_in_t1, all_items_in_t2):
yield highlight_cell(y)
我仍然无法理解这种模式,因为它看起来有点令人困惑。谁能解释得更清楚一点吗
1个回答
0
投票
投票
这里用的是
DataFrame.style.applyDataFrame.apply通过使用参数
axis=Nonet1.map(highlight_cell, props='background-color:yellow')
并使用输出作为格式。
x y
0 background-color:yellow
1 background-color:yellow
2 background-color:yellow
最新问题
- 为什么 esp32 cam car 网站代码不起作用?
- Next.js 如何设置别名?
- 匿名函数中的 If-then-else
- ReactJS 在点击时发送键(索引)
- Apexcharts:将 xTicks 和标签与热图单元格的开头对齐
- 当追溯一致性在 Swift 中实际上发生冲突时会发生什么
- 使用 Slack 工作流程自动化复制 Google 表格
- 如何通过 CMD 或 PowerShell 在 Windows 8 中切换飞行模式
- 获得与我所知相反的意外表达结果
- React Native 图像选择器不工作:任务:react-native-image-picker:compileDebugJavaWithJavac 失败
- Spring-Cloud-Stream serde SerializationException 会阻止消息在被消费和修改后被发布
- `--single-transaction` 相当于 mysqlsh util.dumpSchema
- firebase 电话号码 otp 发送失败
- 无法更改React-tilt默认选项不起作用
- React 编辑器问题
- blocking_king这个方法是不是对#[tauri::command]不满意?
- 如何从单元格范围内的不同字符串中提取特定字母后的数字并对它们求和?
- 用c++格式化驱动器
- 如何在 VS Code 中为我的 Python 程序创建和运行虚拟环境?我想要一些选定的程序在单独的环境中运行
- 恢复解析器精度基准
© www.soinside.com 2019 - 2024. All rights reserved.